Case-Control Analysis
Perform powerful case-control studies to identify disease-associated variants. Bystro's specialized case-control support makes it easy to compare variant frequencies between affected and unaffected individuals, with advanced covariate integration for complex study designs.
Case-control studies are fundamental to genetic research, helping identify:
- • Disease-associated variants and mutations
- • Protective alleles and genetic modifiers
- • Treatment response predictors
- • Population-specific genetic risk factors
Quick Start: Basic Case-Control Setup
Define your study groups
Use custom synonyms to create cases andcontrols shortcuts containing your sample IDs.
With covariate files, you can also define groups by phenotype, treatment response, or any experimental metadata.
Search for case-specific variants
Use cases -controls to find variants present in cases but absent in controls. This powerful query identifies potential disease-associated variants.
Analyze variant distributions
Use Tools → Count by sample id to get detailed statistics showing variant frequencies and distributions across your case-control groups.
Example: Finding Case-Specific Variants
After defining your case and control groups, search for variants that appear only in cases:
Advanced: Statistical Analysis
Beyond simple presence/absence analysis, get detailed statistical summaries of variant distributions across your study groups. This provides the foundation for burden testing and association analysis.
Getting Variant Distribution Statistics
Create your study groups
Define cases and controls synonyms with your sample IDs or use covariate data to define groups by phenotype.
Perform your variant search
Search for variants of interest (rare variants, specific genes, functional categories, etc.).
Get statistical summaries
Click Tools → Count by sample id to access detailed case-control statistics:
Enhanced with Covariate Integration
Powerful New Capabilities
With Bystro's covariate file support, you can now define study groups based on any experimental metadata, not just predefined sample lists. This opens up sophisticated study designs:
Phenotype-Based Grouping
- • Disease severity (mild vs severe)
- • Age of onset (early vs late)
- • Clinical subtypes
- • Biomarker levels
Treatment Response Studies
- • Drug responders vs non-responders
- • Adverse event occurrence
- • Dosage requirements
- • Treatment duration
Specialized Analysis Types
De Novo Variant Discovery
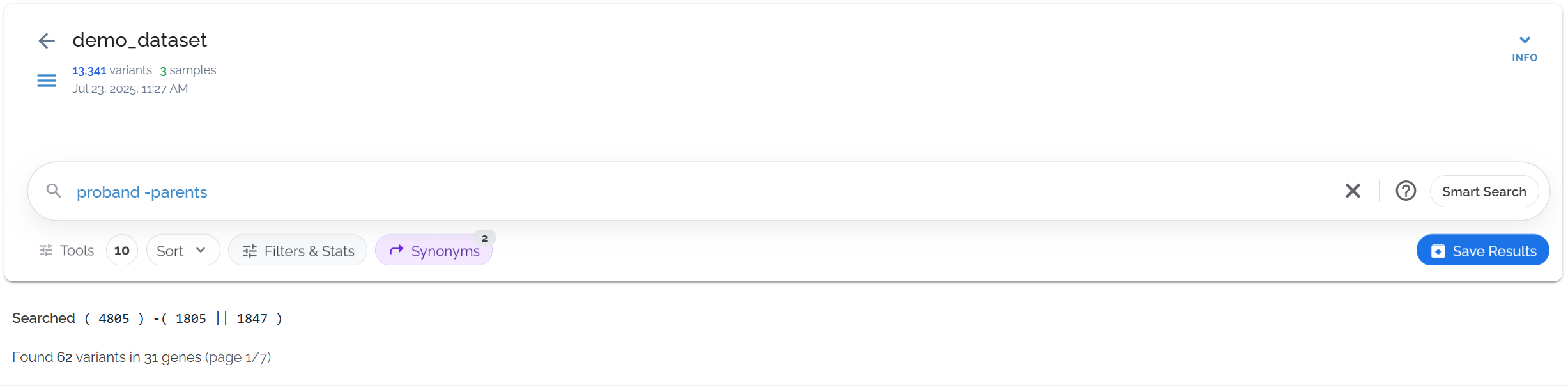
Use family-based case-control designs to identify de novo mutations:
probands -parentsFinds variants in affected children that are absent in unaffected parents
Compound Heterozygosity
Automatically detect compound heterozygous patterns:
Bystro reports compound heterozygosity regardless of case-control status, identifying recessive disease patterns
Discovering de novo variants by using custom synonyms
Quality Considerations
Be aware of sample inclusion criteria that may affect results:
VCF Format
Includes all samples with non-reference calls, excluding only those with missing genotypes
SNP Format
Excludes samples with <95% call confidence and ambiguous genotypes (N)
Impact on Analysis
Case-Control Studies
Low-quality or miscalled samples included in queries may lead to inaccurate case-control associations. Always review sample quality metrics.
De Novo Analysis
Poor-quality parental calls may falsely suggest de novo variants. Searchproband -parentsresults should be validated when call quality is uncertain.
Research Applications
Rare Disease Gene Discovery
Combine case-control analysis with rare variant filtering:
cases -controls AND maf < 0.001 AND cadd > 20Pharmacogenomics Studies
Identify genetic variants associated with drug response:
responders -nonResponders AND refSeq.name2:CYP2D6Population Genetics
Compare variant frequencies between populations or ethnic groups:
population1 -population2 AND gnomad.genomes.af < 0.05• Balance your groups: Ensure adequate sample sizes in both cases and controls
• Consider covariates: Use demographic and clinical metadata to define precise study groups
• Validate findings: Confirm significant associations with independent replication cohorts
• Quality control: Review sample quality metrics and exclude poor-quality calls
• Multiple testing: Apply appropriate corrections for genome-wide analysis
Dataset used in examples: 1000 Genomes Project (73,452,337 variants in 27,192 genes, queries typically complete in ~0.5 seconds)